
Editor’s note: This post from Lukas Pustina, Performance Engineer at codecentric, originally appeared on the codecentric blog.
This is the first in a new series of guest blog posts, written by real sysdig users telling their own stories in their own words. If you’re interested in posting here, please reach out – we’d love to hear from you!
This is the story of how the tiniest things can sometimes be the biggest culprits. First and foremost, this is a detective story. So come and follow me on a little crime scene investigation that uncovered an incredibly counterintuitive and almost criminal default setting in Ubuntu 14.04 crippling the virtual network performance along with it’s network latency.
And just in case you don’t like detective stories – and this goes out to all you nerds out there – I promise it will be worth your while, because this is also an introduction to keepalived, tcpdump, and sysdig. So sit back and enjoy!
The problems came out of the blue. We were running an OpenStack installation for the next generation CenterDevice cloud.
CenterDevice is a cloud-based document solution and our clients rely on its 24/7 availability. In order to achieve this availability, all our components are multiply redundant. For example, our load balancers are two separate virtual machines running HAProxy. Both instances manage a highly available IP address via keepalived.
This system worked very well, until both load balancers became the victims of an evil crime. Both virtual machines started flapping their highly available virtual IP addresses and we were receiving alerting e-mails by the dozens, but there was no obvious change to the system that could have explained this behavior.
And this is how the story begins.
When I was called to investigate this weird behavior and answer the question of what was happening to the poor little load balancers, I started by taking a close look at the crime scene: keepalived. The following listing shows our master configuration of keepalived on virtual host loadbalancer011
% sudo cat /etc/keepalived/keepalived.conf
global_defs {
notification_email {
[email protected]
}
notification_email_from [email protected]
smtp_server 10.10.9.8
smtp_connect_timeout 30
router_id loadbalancer01
}
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
vrrp_instance loadbalancer {
state MASTER
interface eth0
virtual_router_id 205
priority 101
smtp_alert
advert_int 1
authentication {
auth_type PASS
auth_pass totally_secret
}
virtual_ipaddress {
192.168.205.7
}
track_script {
chk_haproxy
}
}
The same configuration on our second load balancer loadbalancer02 looks exactly the same, with notification email and router id changed accordingly as well as a lower priority. This all looked fine to me and it was immediately clear that keepalived.conf was not the one to blame. I needed to figure out a different reason why the two keepalived were continuously flapping the virtual IP address.
Now, it is important to understand how VRRP (the protocol keepalived uses to check the availability of its partners) works. All partners continuously exchange keep alive packets via the multicast address vrrp.mcast.net which resolves to 224.0.0.18. These packets use IP protocol number 112. If the backup does not receive these keep alive packets from the current master, it assumes the partner is dead, murdered, or has otherwise gone AWOL and takes over the virtual IP address, now acting as the new master. If the old master decides to check back in, the virtual IP address is exchanged again.
Since we were observing this back and forth exchange, I suspected the virtual network had unlawfully disregarded its responsibility. I immediately rushed to the terminal and started to monitor the traffic. This might seem easy, but it is far more complex than you think. The figure below, taken from openstack.redhat.com, shows an overview of how Neutron creates virtual networks.

Since both load balancers were running on different nodes, the VRRP packets traveled from A to J and back to Q. So where were the missing packets?
I decided to tail the packets at A, E, and J. Maybe that was where the culprit was hiding. I started tcpdump on loadbalancer01, the compute node node01, and the network controller control01 looking for missing packets. And there were packets. Lots of packets. But I could not see missing packets until I stopped tcpdump:
$ tcpdump -l host vrrp.mcast.net ... 45389 packets captured 699 packets received by filter 127 packets dropped by kernel
Dropped packets by the kernel? Were these our victims? Unfortunately not.
Not very helpful when you are trying to find where packets get, well, dropped. But there is the handy parameter -B for tcpdump that increases this buffer. I tried again:
$ tcpdump -l -B 10000 host vrrp.mcast.net
Much better, no more dropped packets by the kernel. And now, I saw something. While the VRRP packets were dumped on my screen, I noticed that sometimes there was a lag time of longer than one second between VRRP keepalives. This struck me as odd. This should not happen as the interval for VRRP packets had been set to one second in the configurations. I felt that I was on to something, but just needed to dig a bit deeper.
I let tcpdump show me the time differences between succeeding packets and detect differences bigger than one second.
$ tcpdump -i any -l -B 10000 -ttt host vrrp.mcast.net | grep -v '^00:00:01'
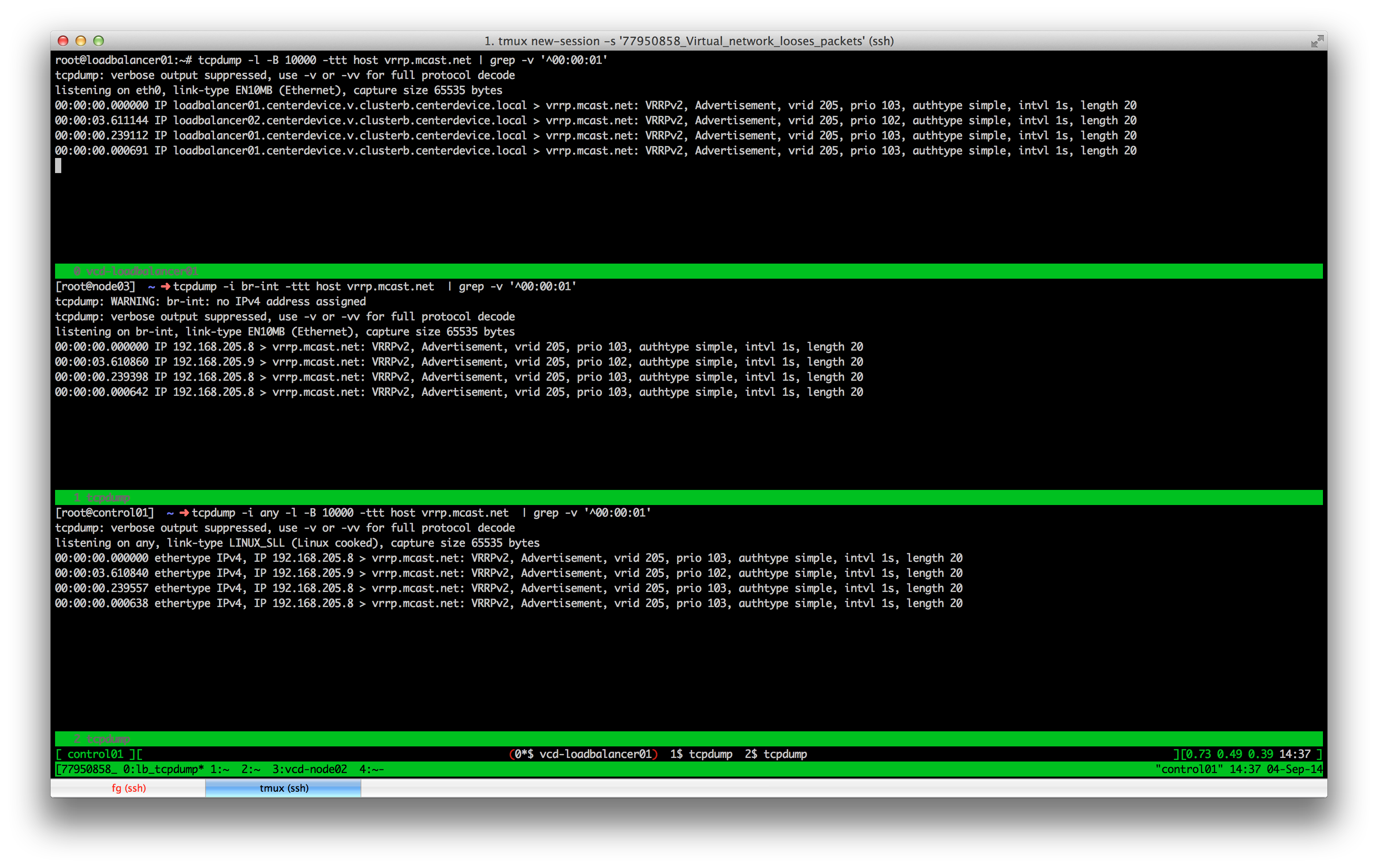
Oh my god. Look at the screenshot above 2. There is a delay of more than 3.5 seconds. Of course loadbalancer02 assumes his partner went MIA.
But wait, the delay already starts on loadbalancer01? I have been fooled! It is not the virtual network. It had to be the master keepalived host! But why? Why should the virtual machine hold packets back? There must be some evil hiding in this machine and I will find and face it…
After discovering the culprit might be hiding inside the virtual machine, I fetched my assistant sysdig and we ssh’ed into loadblancer01. Together, we started to ask questions – very intense, uncomfortable questions to finally get to the bottom of this.
Sysdig being the good detective assistant went to work immediately and kept a transcript about all questions and answers in a file.
$ sysdig -w transcript
I was especially interested in the sendmsg syscall that actually sends network packets issued by the keepalived process.
I was interested in the invocation, which is the event direction from user process to kernel.
$ sysdig -r transcript proc.name=keepalived and evt.type=sendmsg and evt.dir='>'
That stirred up quite some evidence. But I wanted to find the time gaps larger than one second. I drew Lua from my concealed holster inside my jacket and fired a quick chisel right between two sendmsg syscalls:
$ sysdig -r transcript -c find_time_gap proc.name=keepalived and evt.type=sendmsg and evt.dir='>' 370964 17:01:26.375374738 (5.03543187) keepalived > sendmsg fd=13(192.168.205.8->224.0.0.18) size=40 tuple=0.0.0.0:112->224.0.0.18:0
Got you! A time gap of more than five seconds turned up. I inspected the events closely looking for event number 370964.
$ sysdig -r transcript proc.name=keepalived and evt.type=sendmsg and evt.dir='>' | grep -C 1 370964 368250 17:01:21.339942868 0 keepalived (10400) > sendmsg fd=13(192.168.205.8->224.0.0.18) size=40 tuple=0.0.0.0:112->224.0.0.18:0 370964 17:01:26.375374738 1 keepalived (10400) > sendmsg fd=13(192.168.205.8->224.0.0.18) size=40 tuple=0.0.0.0:112->224.0.0.18:0 371446 17:01:26.377770247 1 keepalived (10400) > sendmsg fd=13(192.168.205.8->224.0.0.18) size=40 tuple=0.0.0.0:112->224.0.0.18:0
There, in lines 1 and 2. There it was. A gap much larger than one second. Now it was clear. The perpetrator was hiding inside the virtual machine causing lags in the processing of keepalived’s sendmsg. But who was it?
After some ruling out of innocent bystanders, I found this:
$ sysdig -r transcript | tail -n +368250 | grep -v "keepalived|haproxy|zabbix" 369051 17:01:23.621071175 3 (0) > switch next=7 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369052 17:01:23.621077045 3 (7) > switch next=0 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369053 17:01:23.625105578 3 (0) > switch next=7 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369054 17:01:23.625112785 3 (7) > switch next=0 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369055 17:01:23.628568892 3 (0) > switch next=25978(sysdig) pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369056 17:01:23.628597921 3 sysdig (25978) > switch next=0 pgft_maj=0 pgft_min=2143 vm_size=99684 vm_rss=6772 vm_swap=0 369057 17:01:23.629068124 3 (0) > switch next=7 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369058 17:01:23.629073516 3 (7) > switch next=0 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369059 17:01:23.633104746 3 (0) > switch next=7 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369060 17:01:23.633110185 3 (7) > switch next=0 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369061 17:01:23.637061129 3 (0) > switch next=7 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369062 17:01:23.637065648 3 (7) > switch next=0 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369063 17:01:23.641104396 3 (0) > switch next=7 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369064 17:01:23.641109883 3 (7) > switch next=0 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369065 17:01:23.645069607 3 (0) > switch next=7 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369066 17:01:23.645075551 3 (7) > switch next=0 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369067 17:01:23.649071836 3 (0) > switch next=7 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369068 17:01:23.649077700 3 (7) > switch next=0 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369069 17:01:23.653073066 3 (0) > switch next=7 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369070 17:01:23.653078791 3 (7) > switch next=0 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369071 17:01:23.657069807 3 (0) > switch next=7 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369072 17:01:23.657075525 3 (7) > switch next=0 pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369073 17:01:23.658678681 3 (0) > switch next=25978(sysdig) pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 369074 17:01:23.658698453 3 sysdig (25978) > switch next=0 pgft_maj=0 pgft_min=2143 vm_size=99684 vm_rss=6772 vm_swap=0
The processes masked behind pids 0 and 7 were consuming the virtual CPU. 0 and 7? These low process ids indicate kernel threads! I double checked with sysdig’s supervisor, just to be sure. I was right.
The kernel, the perpetrator? This hard working, ever reliable guy? No, I could not believe it. There must be more. And by the way, the virtual machine was not under load. So what could the virtual machine’s kernel be doing … except … not doing anything at all? Maybe it was waiting for IO! Could that be? Since all hardware of a virtual machine is, well, virtual, the IO wait could only be on the baremetal level.
I left loadbalancer01 for its bare metal node01. On my way, I was trying to wrap my head around what was happening. What was this all about? So many proxies, so many things happening in the shadows. So many false suspects. This is not a regular case. There is something much more vicious happening behind the scenes. I must find it…
When I arrived at baremetal host node01, hosting virtual host loadbalancer01, I was anxious to see the IO statistics. The machine must be under heavy IO load when the virtual machine’s messages are waiting for up to five seconds.
I switched on my iostat flashlight and saw this:
$ iostat Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 12.00 0.00 144.00 0 144 sdc 0.00 0.00 0.00 0 0 sdb 6.00 0.00 24.00 0 24 sdd 0.00 0.00 0.00 0 0 sde 0.00 0.00 0.00 0 0 sdf 20.00 0.00 118.00 0 118 sdg 0.00 0.00 0.00 0 0 sdi 22.00 0.00 112.00 0 112 sdh 0.00 0.00 0.00 0 0 sdj 0.00 0.00 0.00 0 0 sdk 21.00 0.00 96.50 0 96 sdl 0.00 0.00 0.00 0 0 sdm 9.00 0.00 64.00 0 64
Nothing? Nothing at all? No IO on the disks? Maybe my bigger flashlight iotop could help:
$ iotop
Unfortunately, what I saw was too ghastly to show here and therefore I decided to omit the screenshots of iotop3. It was pure horror. Six qemu processes eating the physical CPUs alive in IO.
So, no disk IO, but super high IO caused by qemu. It must be network IO then. But all performance counters show almost no network activity. What if this IO wasn’t real, but virtual? It could be the virtual network driver! It had to be the virtual network driver.
I checked the OpenStack configuration. It was set to use the para-virtualized network driver vhost_net.
I checked the running qemu processes. They were also configured to use the para-virtualized network driver.
$ ps aux | grep qemu libvirt+ 6875 66.4 8.3 63752992 11063572 ? Sl Sep05 4781:47 /usr/bin/qemu-system-x86_64 -name instance-000000dd -S ... -netdev tap,fd=25,id=hostnet0,vhost=on,vhostfd=27 ...
I was getting closer! I checked the kernel modules. Kernel module vhost_net was loaded and active.
$ lsmod | grep net vhost_net 18104 2 vhost 29009 1 vhost_net macvtap 18255 1 vhost_net
I checked the qemu-kvm configuration and froze.
$ cat /etc/default/qemu-kvm # To disable qemu-kvm's page merging feature, set KSM_ENABLED=0 and # sudo restart qemu-kvm KSM_ENABLED=1 SLEEP_MILLISECS=200 # To load the vhost_net module, which in some cases can speed up # network performance, set VHOST_NET_ENABLED to 1. VHOST_NET_ENABLED=0 # Set this to 1 if you want hugepages to be available to kvm under # /run/hugepages/kvm KVM_HUGEPAGES=0
vhost_net was disabled by default for qemu-kvm. We were running all packets through userspace and qemu instead of passing them to the kernel directly as vhost_net does! That’s where the lag was coming from!
I acted immediately to rescue the victims. I made the huge, extremely complicated, full 1 byte change on all our compute nodes by modifying a VHOST_NET_ENABLED=0 to a VHOST_NET_ENABLED=1, restarted all virtual machines and finally, after days of constantly screaming in pain, the flapping between both load balancers stopped.
I did it! I saved them!
But I couldn’t stop here. I wanted to find out, who did that to the poor little load balancers. Who was behind this conspiracy of crippled network latency?
I knew there was only one way to finally catch the guy. I set a trap. I installed a fresh, clean, virgin Ubuntu 14.04 in a virtual machine and then, well, then I waited — for apt-get install qemu-kvm to finish:
$ sudo apt-get install qemu-kvm Reading package lists... Done Building dependency tree Reading state information... Done The following extra packages will be installed: acl cpu-checker ipxe-qemu libaio1 libasound2 libasound2-data libasyncns0 libbluetooth3 libboost-system1.54.0 libboost-thread1.54.0 libbrlapi0.6 libcaca0 libfdt1 libflac8 libjpeg-turbo8 libjpeg8 libnspr4 libnss3 libnss3-nssdb libogg0 libpulse0 librados2 librbd1 libsdl1.2debian libseccomp2 libsndfile1 libspice-server1 libusbredirparser1 libvorbis0a libvorbisenc2 libxen-4.4 libxenstore3.0 libyajl2 msr-tools qemu-keymaps qemu-system-common qemu-system-x86 qemu-utils seabios sharutils Suggested packages: libasound2-plugins alsa-utils pulseaudio samba vde2 sgabios debootstrap bsd-mailx mailx The following NEW packages will be installed: acl cpu-checker ipxe-qemu libaio1 libasound2 libasound2-data libasyncns0 libbluetooth3 libboost-system1.54.0 libboost-thread1.54.0 libbrlapi0.6 libcaca0 libfdt1 libflac8 libjpeg-turbo8 libjpeg8 libnspr4 libnss3 libnss3-nssdb libogg0 libpulse0 librados2 librbd1 libsdl1.2debian libseccomp2 libsndfile1 libspice-server1 libusbredirparser1 libvorbis0a libvorbisenc2 libxen-4.4 libxenstore3.0 libyajl2 msr-tools qemu-keymaps qemu-kvm qemu-system-common qemu-system-x86 qemu-utils seabios sharutils 0 upgraded, 41 newly installed, 0 to remove and 2 not upgraded. Need to get 3631 kB/8671 kB of archives. After this operation, 42.0 MB of additional disk space will be used. Do you want to continue? [Y/n] < ... Setting up qemu-system-x86 (2.0.0+dfsg-2ubuntu1.3) ... qemu-kvm start/running Setting up qemu-utils (2.0.0+dfsg-2ubuntu1.3) ... Processing triggers for ureadahead (0.100.0-16) ... Setting up qemu-kvm (2.0.0+dfsg-2ubuntu1.3) ... Processing triggers for libc-bin (2.19-0ubuntu6.3) ...
And then, I let the trap snap:
$ cat /etc/default/qemu-kvm # To disable qemu-kvm's page merging feature, set KSM_ENABLED=0 and # sudo restart qemu-kvm KSM_ENABLED=1 SLEEP_MILLISECS=200 # To load the vhost_net module, which in some cases can speed up # network performance, set VHOST_NET_ENABLED to 1. VHOST_NET_ENABLED=0 # Set this to 1 if you want hugepages to be available to kvm under # /run/hugepages/kvm KVM_HUGEPAGES=0
I could not believe it! It was Ubuntu’s own default setting. Ubuntu, the very foundation of our cloud, decided to turn vhost_net off by default, despite all modern hardware supporting it. Ubuntu was convicted and I could finally rest.
This is the end of my detective story. I found and arrested the criminal Ubuntu default setting and was able to prevent him from further crippling our virtual network latencies.
Please feel free to contact me and ask questions about the details of my journey. I’m already negotiating to sell the movie rights. But maybe there will be another season of OpenStack Crime Investigation in the future. So stay tuned!
Footnotes
1. All personal details like IP, E-Mail addresses etc. have been changed to protect the innocent. ⏎
2. Yes, you see correctly. I am running screen inside tmux . This allows me to sustain the screen tabs even during logouts. ⏎
3. Eh, and because I lost them. ⏎